Hypothesis testing¶
Elements¶
Null hypothesis:
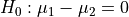
Alternative hypothesis
Test statistics: e.g.,
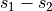
The distribution of test statistics: T-distribution
Rejection region
P-value¶
The probability to observe the difference under the null hypothesis (more formally speaking, the probability to observe the current value and more extremed values)

one-tail or two-tail P-value?¶
Depending on the null hypothesis (e.g., 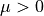 or
or 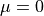 ).
).
Most software will choose two-tail p-value as default.
One-tail p-value is always smaller than two-tail p-value (simply divided by two).
Type 1 error¶
The probability to make a false claim
False discovery rate (adjusted p-value)¶
The probability to make a false claim in multiple hypotheses testing
T-test¶
Comparing two samples.
Two independent samples:
equal variance (student’s t-test)
unequal variance (welch’s t-test)
Paired samples:
-Paired t-test
ANOVA (Analysis of Variance)¶
One-way ANOVA, comparing the mead differences across two or more groups (which is basically multiple t-tests, but with better adjustment for Type 1 error).
[2]:
import pandas as pd
from scipy.stats import ttest_ind
from scipy.stats import ttest_rel
from statsmodels.stats.multitest import multipletests
[3]:
df = pd.read_csv("/home/yli11/tmp/results.KO_vs_WT.csv",sep="\t",index_col=0)
df.head()
[3]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | ||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 |
[4]:
# extract column names, you can also just type column names manually
WT_column_names = [x for x in df.columns if "WT" in x] # When using only 'if', put 'for' in the beginning
KO_column_names = [x for x in df.columns if "KO" in x] # When using only 'if', put 'for' in the beginning
print (WT_column_names)
print (KO_column_names)
['WT_1_log2CPM', 'WT_2_log2CPM', 'WT_3_log2CPM']
['KO_1_log2CPM', 'KO_2_log2CPM', 'KO_3_log2CPM']
[ ]:
ttest_ind([1,2,3],[1,2,3])
[5]:
## Student t-test
def student_t_test(r):
return ttest_ind(r[WT_column_names],r[KO_column_names],equal_var=True).pvalue
df['student_t_test'] = df.apply(student_t_test,axis=1)
df.head()
[5]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | |||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 |
[6]:
## Welch t-test
def welch_t_test(r):
return ttest_ind(r[WT_column_names],r[KO_column_names],equal_var=False).pvalue
df['welch_t_test'] = df.apply(welch_t_test,axis=1)
df.head()
[6]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | welch_t_test | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | ||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 | 2.647881e-08 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 | 3.688665e-05 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 | 1.024245e-05 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 | 3.596084e-04 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 | 4.948437e-06 |
[7]:
## paired t-test
def paired_t_test(r):
return ttest_rel(r[WT_column_names],r[KO_column_names]).pvalue
df['paired_t_test'] = df.apply(paired_t_test,axis=1)
df.head()
[7]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | welch_t_test | paired_t_test | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | |||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 | 2.647881e-08 | 0.000083 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 | 3.688665e-05 | 0.000142 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 | 1.024245e-05 | 0.000051 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 | 3.596084e-04 | 0.000706 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 | 4.948437e-06 | 0.000266 |
[27]:
df.shape
[27]:
(15801, 21)
calculate FDR¶
[8]:
?multipletests
Signature:
multipletests(
pvals,
alpha=0.05,
method='hs',
is_sorted=False,
returnsorted=False,
)
Docstring:
Test results and p-value correction for multiple tests
Parameters
----------
pvals : array_like, 1-d
uncorrected p-values. Must be 1-dimensional.
alpha : float
FWER, family-wise error rate, e.g. 0.1
method : str
Method used for testing and adjustment of pvalues. Can be either the
full name or initial letters. Available methods are:
- `bonferroni` : one-step correction
- `sidak` : one-step correction
- `holm-sidak` : step down method using Sidak adjustments
- `holm` : step-down method using Bonferroni adjustments
- `simes-hochberg` : step-up method (independent)
- `hommel` : closed method based on Simes tests (non-negative)
- `fdr_bh` : Benjamini/Hochberg (non-negative)
- `fdr_by` : Benjamini/Yekutieli (negative)
- `fdr_tsbh` : two stage fdr correction (non-negative)
- `fdr_tsbky` : two stage fdr correction (non-negative)
is_sorted : bool
If False (default), the p_values will be sorted, but the corrected
pvalues are in the original order. If True, then it assumed that the
pvalues are already sorted in ascending order.
returnsorted : bool
not tested, return sorted p-values instead of original sequence
Returns
-------
reject : ndarray, boolean
true for hypothesis that can be rejected for given alpha
pvals_corrected : ndarray
p-values corrected for multiple tests
alphacSidak : float
corrected alpha for Sidak method
alphacBonf : float
corrected alpha for Bonferroni method
Notes
-----
There may be API changes for this function in the future.
Except for 'fdr_twostage', the p-value correction is independent of the
alpha specified as argument. In these cases the corrected p-values
can also be compared with a different alpha. In the case of 'fdr_twostage',
the corrected p-values are specific to the given alpha, see
``fdrcorrection_twostage``.
The 'fdr_gbs' procedure is not verified against another package, p-values
are derived from scratch and are not derived in the reference. In Monte
Carlo experiments the method worked correctly and maintained the false
discovery rate.
All procedures that are included, control FWER or FDR in the independent
case, and most are robust in the positively correlated case.
`fdr_gbs`: high power, fdr control for independent case and only small
violation in positively correlated case
**Timing**:
Most of the time with large arrays is spent in `argsort`. When
we want to calculate the p-value for several methods, then it is more
efficient to presort the pvalues, and put the results back into the
original order outside of the function.
Method='hommel' is very slow for large arrays, since it requires the
evaluation of n partitions, where n is the number of p-values.
File: ~/.conda/envs/captureC/lib/python3.8/site-packages/statsmodels/stats/multitest.py
Type: function
[15]:
df['bon_FDR'] = multipletests(df['student_t_test'],method="bonferroni")[1]
df.head()
[15]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | welch_t_test | paired_t_test | bon_FDR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | ||||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 | 2.647881e-08 | 0.000083 | 0.000389 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 | 3.688665e-05 | 0.000142 | 0.025666 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 | 1.024245e-05 | 0.000051 | 0.005908 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 | 3.596084e-04 | 0.000706 | 0.055211 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 | 4.948437e-06 | 0.000266 | 0.025729 |
[16]:
df['hs_FDR'] = multipletests(df['student_t_test'],method="hs")[1]
df.head()
[16]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | welch_t_test | paired_t_test | bon_FDR | hs_FDR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | |||||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 | 2.647881e-08 | 0.000083 | 0.000389 | 0.000389 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 | 3.688665e-05 | 0.000142 | 0.025666 | 0.025285 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 | 1.024245e-05 | 0.000051 | 0.005908 | 0.005887 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 | 3.596084e-04 | 0.000706 | 0.055211 | 0.053546 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 | 4.948437e-06 | 0.000266 | 0.025729 | 0.025346 |
[17]:
df['bh_FDR'] = multipletests(df['student_t_test'],method="fdr_bh")[1]
df.head()
[17]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | welch_t_test | paired_t_test | bon_FDR | hs_FDR | bh_FDR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | ||||||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 | 2.647881e-08 | 0.000083 | 0.000389 | 0.000389 | 0.000367 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 | 3.688665e-05 | 0.000142 | 0.025666 | 0.025285 | 0.000715 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 | 1.024245e-05 | 0.000051 | 0.005908 | 0.005887 | 0.000537 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 | 3.596084e-04 | 0.000706 | 0.055211 | 0.053546 | 0.001062 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 | 4.948437e-06 | 0.000266 | 0.025729 | 0.025346 | 0.000715 |
[18]:
df['bh_FDR2'] = multipletests(df['P.Value'],method="fdr_bh")[1]
df.head()
[18]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | welch_t_test | paired_t_test | bon_FDR | hs_FDR | bh_FDR | bh_FDR2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | |||||||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 | 2.647881e-08 | 0.000083 | 0.000389 | 0.000389 | 0.000367 | 3.597572e-11 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 | 3.688665e-05 | 0.000142 | 0.025666 | 0.025285 | 0.000715 | 9.095056e-09 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 | 1.024245e-05 | 0.000051 | 0.005908 | 0.005887 | 0.000537 | 1.092323e-08 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 | 3.596084e-04 | 0.000706 | 0.055211 | 0.053546 | 0.001062 | 1.598640e-08 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 | 4.948437e-06 | 0.000266 | 0.025729 | 0.025346 | 0.000715 | 1.598640e-08 |
most commonly used FDR methods¶
Usually you can significant results using the BH method. Other methods tend to be more conservative, hard to say which one is more conservative, it depends on number of samples and the actual p-value ranks.
BH
Bonferroni
[23]:
## One-way ANOVA
from scipy.stats import f_oneway
def anova(r):
return f_oneway(r[WT_column_names],r[KO_column_names]).pvalue
df['anova'] = df.apply(anova,axis=1)
df.head()
[23]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | KO_2_log2CPM | KO_3_log2CPM | student_t_test | welch_t_test | paired_t_test | bon_FDR | hs_FDR | bh_FDR | bh_FDR2 | anova | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | ||||||||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | 7.8119 | 7.8218 | 2.461504e-08 | 2.647881e-08 | 0.000083 | 0.000389 | 0.000389 | 0.000367 | 3.597572e-11 | 2.461504e-08 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | 4.9264 | 4.9864 | 1.624300e-06 | 3.688665e-05 | 0.000142 | 0.025666 | 0.025285 | 0.000715 | 9.095056e-09 | 1.624300e-06 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | 7.2202 | 7.1495 | 3.738815e-07 | 1.024245e-05 | 0.000051 | 0.005908 | 0.005887 | 0.000537 | 1.092323e-08 | 3.738815e-07 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | 2.2622 | 2.0040 | 3.494130e-06 | 3.596084e-04 | 0.000706 | 0.055211 | 0.053546 | 0.001062 | 1.598640e-08 | 3.494130e-06 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | 3.9610 | 4.0665 | 1.628337e-06 | 4.948437e-06 | 0.000266 | 0.025729 | 0.025346 | 0.000715 | 1.598640e-08 | 1.628337e-06 |
[26]:
## One-way ANOVA
from scipy.stats import f_oneway
def anova(r):
return f_oneway(r[WT_column_names],r[KO_column_names],r[WT_column_names+KO_column_names]).pvalue
df['anova2'] = df.apply(anova,axis=1)
df.head()
[26]:
| logFC | AveExpr | t | P.Value | adj.P.Val | B | WT_1_log2CPM | WT_2_log2CPM | WT_3_log2CPM | KO_1_log2CPM | ... | KO_3_log2CPM | student_t_test | welch_t_test | paired_t_test | bon_FDR | hs_FDR | bh_FDR | bh_FDR2 | anova | anova2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gene | |||||||||||||||||||||
| D17H6S56E-5 | -3.0830 | 9.3418 | -97.669 | 2.276800e-15 | 3.597600e-11 | 25.102 | 10.8880 | 10.9120 | 10.8500 | 7.7671 | ... | 7.8218 | 2.461504e-08 | 2.647881e-08 | 0.000083 | 0.000389 | 0.000389 | 0.000367 | 3.597572e-11 | 2.461504e-08 | 0.044245 |
| Scd1 | -2.2133 | 6.1060 | -50.068 | 1.151200e-12 | 9.095200e-09 | 19.799 | 7.2574 | 7.1911 | 7.1920 | 5.0828 | ... | 4.9864 | 1.624300e-06 | 3.688665e-05 | 0.000142 | 0.025666 | 0.025285 | 0.000715 | 9.095056e-09 | 1.624300e-06 | 0.044609 |
| Coro2a | -1.4558 | 7.9154 | -46.998 | 2.073900e-12 | 1.092300e-08 | 19.285 | 8.6433 | 8.6614 | 8.6256 | 7.1924 | ... | 7.1495 | 3.738815e-07 | 1.024245e-05 | 0.000051 | 0.005908 | 0.005887 | 0.000537 | 1.092323e-08 | 3.738815e-07 | 0.044393 |
| Plxnb2 | -2.9373 | 3.6346 | -42.033 | 5.854300e-12 | 1.598600e-08 | 17.639 | 5.0743 | 5.1443 | 5.1107 | 2.2122 | ... | 2.0040 | 3.494130e-06 | 3.596084e-04 | 0.000706 | 0.055211 | 0.053546 | 0.001062 | 1.598640e-08 | 3.494130e-06 | 0.044804 |
| Gzmb | -1.8469 | 4.9198 | -41.606 | 6.436800e-12 | 1.598600e-08 | 18.097 | 5.7934 | 5.8635 | 5.8686 | 3.9655 | ... | 4.0665 | 1.628337e-06 | 4.948437e-06 | 0.000266 | 0.025729 | 0.025346 | 0.000715 | 1.598640e-08 | 1.628337e-06 | 0.044610 |
5 rows × 21 columns
[ ]:
[ ]: